¿Quieres que nos juguemos el café? Mira, vamos a lanzar un dado por turnos e ir sumando los resultados que vayamos obteniendo. Gana el primero que con su tirada pase del número de caras del dado. Llevo mis dados de Magic en el bolsillo, vamos a usar el de 20 para añadir un poco de emoción, así que ganará el primero que llegue a 20. ¿Vale? Empiezas tú. Tiras, sacas un 7, no llegas a 20. Tiro yo, saco un 6: 7+6=13, no llego a 20, tira. Sacas un 12: 13+12=25, ganas. ¡Mier…,! ¡Uy, perdón, eso sí que no me lo esperaba! ¿Al mejor de tres?
(2 horas antes)
Estaba leyendo la autobiografía matemática de John Allen Paulos y en un momento dado cita un artículo suyo en ABCnews con apariciones estelares (la primera, literalmente) del número e. Una de ellas es, traduzco (y abrevio):

John Allen Paulos
Escoger números al azar también puede dar lugar a e. Elige un número entero aleatorio entre 1 y 1000. (Digamos que escoges 381.) Elige otro número aleatorio (digamos 191) y súmalo al primero (en este caso, da 572). Continua eligiendo números aleatorios entre 1 y 1000 y sumándolos a la suma de los números aleatorios escogidos previamente. Detente sólo cuando la suma supere los 1000. (Si el tercer número fuera 613, por ejemplo, la suma pasaría de 1000 después de tres selecciones.)
¿Cuántos números aleatorios, en promedio, necesitarás elegir? En otras palabras, si un grupo grande de personas repite este procedimiento, generar números entre 1 y 1000 y sumarlos hasta que la suma pase de 1000 y registrar el número de selecciones que han necesitado para llegar superar el 1000, el número promedio de dichas selecciones sería –lo has adivinado– muy próximo a e.
Pues sí, en la página del Wolfram Mathworld sobre la distribución de sumas de copias de una variable uniforme en [0,1] encontraréis la demostración de que si vais tomando números al azar entre 0 y 1 con distribución uniforme y sumándolos, la probabilidad de que la primera elección en la que la suma sea 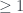
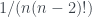
Naturalmente, aunque lanzar un dado de N caras sea escoger un número entero al azar (y equiprobablemente) entre 1 y N, si N es pequeño entonces los decimales que se borran juegan un papel importante. Por ejemplo, con un dado de 6 caras, el número medio de lanzamientos necesarios para sumar 6 o més es un poco más de 2.16, y con un dado de 20 caras para superar el 20 necesitamos en promedio un poco más de 2.52. Con el dado de 100 caras que todos los matemáticos tenemos en casa rondamos el 2.68.

Pero hay otro dato que me interesa en el juego de tirar el dado y sumar hasta superar el umbral: si jugamos con un dado de N caras, más de la mitad de las veces llegaremos a N en la segunda tirada, independientemente de N. Esta probabilidad es muy sencilla de calcular: para pasar de N en la segunda tirada pero no en la primera, tenemos que sacar un k entre 1 y N-1 en la primera tirada y luego en la segunda cualquiera de los k+1 valores que hacen que la suma supere N (por ejemplo, si con un dado de 20 caras en la primera tirada saco un 5, para llegar a 20 en la segunda necesito algo entre 15 y 20). Por tanto, de las 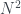
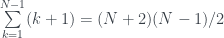

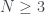
Así que en el jueguecito del principio, si dejamos empezar al otro, lo más probable es que ganemos en la segunda jugada, independientemente del dado. Y si no, siempre nos queda la cuarta, la sexta…
-Hola, Cesc, te veo muy concentrado
-¡Hola! Sí, estaba haciendo unos cálculos. Oye, ¿quieres que nos juguemos el café? Mira, vamos a lanzar un dado por turnos…
Esta entrada participa en la Edición 8.5 del Carnaval de Matemáticas cuyo anfitrión es Raíz de 2.
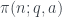 el número de primos
el número de primos  que son congruentes con
que son congruentes con  módulo
módulo  ; supondremos siempre que
; supondremos siempre que  indica el número de todos los primos
indica el número de todos los primos  y
y 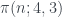 son los números de primos menores o iguales a
son los números de primos menores o iguales a  que son congruentes con 1 y con 3 módulo 4, respectivamente.
que son congruentes con 1 y con 3 módulo 4, respectivamente. , la fracción
, la fracción 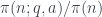 tiende a
tiende a 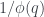 (donde
(donde  es la función de Euler que nos da el número de restos módulo
es la función de Euler que nos da el número de restos módulo 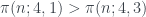 es en
es en 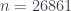 y luego no vuelve a pasar hasta
y luego no vuelve a pasar hasta 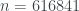 . No obstante, un teorema de Littlewood garantiza que el signo de
. No obstante, un teorema de Littlewood garantiza que el signo de  cambia infinitas veces, así que hay infinitas ocasiones en que en las que el 1 gana al 3.
cambia infinitas veces, así que hay infinitas ocasiones en que en las que el 1 gana al 3. son verdaderas, Rubinstein y Sarnak demostraron en 1994 que, en un cierto sentido específico, la “probabilidad” de que
son verdaderas, Rubinstein y Sarnak demostraron en 1994 que, en un cierto sentido específico, la “probabilidad” de que 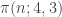 sea mayor que
sea mayor que 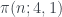 es del 99.6%. Más en general, el teorema de Rubinstein y Sarnak dice que
es del 99.6%. Más en general, el teorema de Rubinstein y Sarnak dice que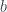 son ambos cuadrados o ambos no cuadrados módulo
son ambos cuadrados o ambos no cuadrados módulo 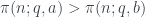 es 0.5
es 0.5 )
)






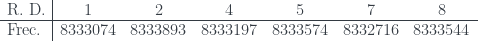
 primos es una miseria.
primos es una miseria.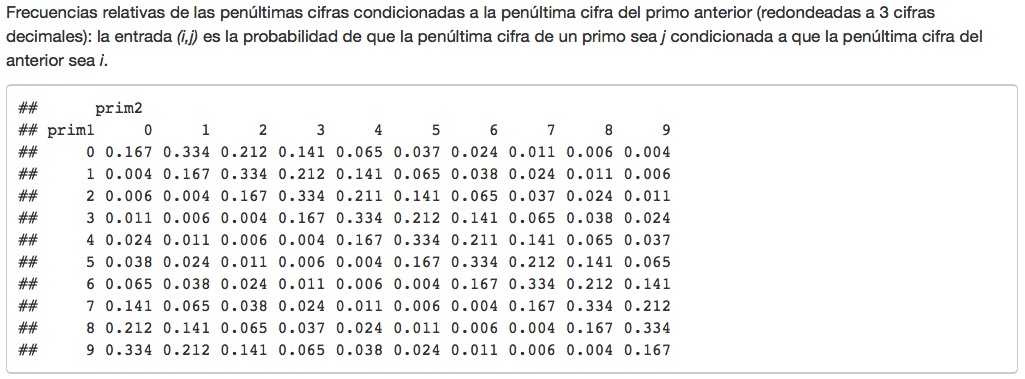


 los números de alumnos de los n cursos que ofrece un determinado centro. Entonces:
los números de alumnos de los n cursos que ofrece un determinado centro. Entonces: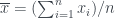
 alumnos, habrá
alumnos, habrá  . La respuesta media por alumno (es decir, el número medio de matriculados en el curso en el que está matriculado un alumno escogido al azar), llamémosle
. La respuesta media por alumno (es decir, el número medio de matriculados en el curso en el que está matriculado un alumno escogido al azar), llamémosle  , se obtendrá dividiendo esta suma por el número de respuestas:
, se obtendrá dividiendo esta suma por el número de respuestas: 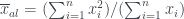
 , un pequeño cálculo algebraico muestra que es igual a la varianza
, un pequeño cálculo algebraico muestra que es igual a la varianza  de
de  . Y ahora es el momento de recordar que la varianza siempre es positiva, y es 0 sólo cuando
. Y ahora es el momento de recordar que la varianza siempre es positiva, y es 0 sólo cuando  . Por lo tanto, salvo en este caso, el número medio de matriculados en el curso de un estudiante escogido al azar será siempre mayor que el número medio de matriculados por curso. Y cuánto mayor sea la varianza, es decir, cuánto más variados sean los números
. Por lo tanto, salvo en este caso, el número medio de matriculados en el curso de un estudiante escogido al azar será siempre mayor que el número medio de matriculados por curso. Y cuánto mayor sea la varianza, es decir, cuánto más variados sean los números 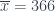 y
y 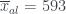 : un estudiante está matriculado de media en un grado de 593 estudiantes, pero el número medio de estudiantes por grado es de 366. Además, un 66.5% de los estudiantes de la UIB están matriculados en grados con un número de estudiantes mayor que la media. Es raro que algunos periódicos tradicionalmente críticos por defecto con la UIB no lo hayan publicado nunca.
: un estudiante está matriculado de media en un grado de 593 estudiantes, pero el número medio de estudiantes por grado es de 366. Además, un 66.5% de los estudiantes de la UIB están matriculados en grados con un número de estudiantes mayor que la media. Es raro que algunos periódicos tradicionalmente críticos por defecto con la UIB no lo hayan publicado nunca. , resolvemos,
, resolvemos, 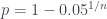 , y desarrollamos por Taylor
, y desarrollamos por Taylor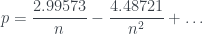
 .
.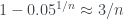 , una cadena de n éxitos tiene una probabilidad inferior al 5%.
, una cadena de n éxitos tiene una probabilidad inferior al 5%.![[0,3/n]](https://s0.wp.com/latex.php?latex=%5B0%2C3%2Fn%5D&bg=ffffff&fg=333A42&s=0&c=20201002) sea un intervalo de confianza del 95% para p ha de pasar que la probabilidad de que p pertenezca a este intervalo sea del 95%. Pero lo que sabemos es que si p no pertenece a este intervalo, la probabilidad de 0 fracasos és (inferior al) 5%. Estamos ante una confusión de probabilidades condicionadas. Sea X el suceso
sea un intervalo de confianza del 95% para p ha de pasar que la probabilidad de que p pertenezca a este intervalo sea del 95%. Pero lo que sabemos es que si p no pertenece a este intervalo, la probabilidad de 0 fracasos és (inferior al) 5%. Estamos ante una confusión de probabilidades condicionadas. Sea X el suceso ![p\in ]3/n,1]](https://s0.wp.com/latex.php?latex=p%5Cin+%5D3%2Fn%2C1%5D&bg=ffffff&fg=333A42&s=0&c=20201002) e
e 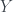 el suceso “Tener 0 fracasos en una secuencia de n experimentos con probabilidad de fracaso p”. Hemos demostrado que
el suceso “Tener 0 fracasos en una secuencia de n experimentos con probabilidad de fracaso p”. Hemos demostrado que 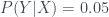 , y lo que querríamos es que
, y lo que querríamos es que  . Y ya sabemos que, al menos en principio,
. Y ya sabemos que, al menos en principio,
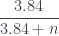 . Por ejemplo, en el caso de los 10 éxitos consecutivos, da el intervalo
. Por ejemplo, en el caso de los 10 éxitos consecutivos, da el intervalo ![[0,0.2774566]](https://s0.wp.com/latex.php?latex=%5B0%2C0.2774566%5D&bg=ffffff&fg=333A42&s=0&c=20201002) , ligeramente más pesimista que la regla del 3. La ventaja de este intervalo
, ligeramente más pesimista que la regla del 3. La ventaja de este intervalo ![\left[0, \dfrac{3.84}{3.84+n}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B0%2C+%5Cdfrac%7B3.84%7D%7B3.84%2Bn%7D%5Cright%5D&bg=ffffff&fg=333A42&s=0&c=20201002) es que éste sí que es un intervalo de confianza al 95% en el sentido usual. Tampoco les costaría tanto a los médicos aprendérselo, ¿no?
es que éste sí que es un intervalo de confianza al 95% en el sentido usual. Tampoco les costaría tanto a los médicos aprendérselo, ¿no?