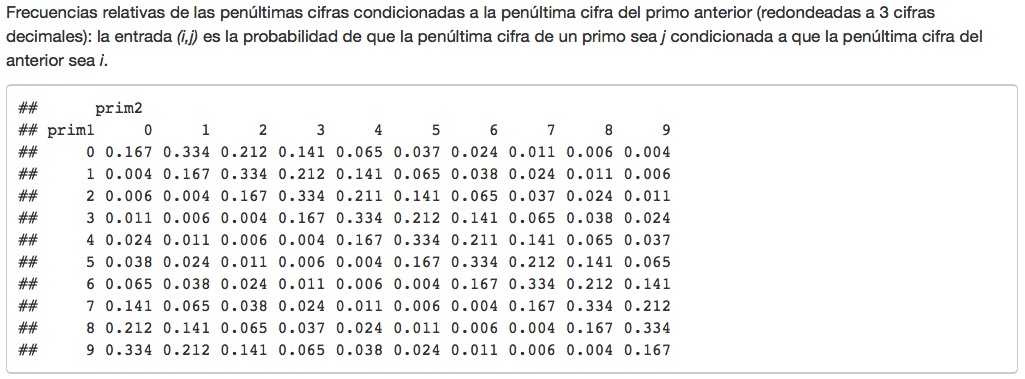
En el #6 de La Visión de Tom King y Gabriel H. Walta (el último incluido en el primer tomo de la edición española de Panini) hay una discusión muy interesante sobre el problema P vs NP. No voy a entrar a discutir las cualidades de esta magnífica serie, ya que podéis consultar si os interesan las reseñas en la Zona Negativa aquí y aquí, e iré al grano. Cuelgo las tres páginas y la coda para que admiréis el dibujo de Walta, y por si os da pereza traducir o la imagen queda muy pequeña, traduzco el texto.

- Como pasa a menudo, aunque trate de complejidades, el problema en si mismo no es complejo.
- Para simplificarlo aun más, descartaré la nomenclatura y me concentraré en los conceptos.
- P representa problemas que un ordenador puede resolver en una cantidad razonable de tiempo. Por ejemplo, la multiplicación. Das dos números a un ordenador, le pides que los multiplique y obtienes la respuesta muy rápido.
- Para obtener dicha respuesta, el ordenador no comprueba todos lo números posibles que podrían encajar en la ecuación. Eso llevaría demasiado tiempo, de tantos números que hay.
- No, el ordenador untilizará un algoritmo, un método, un atajo. Resuelve el problema, no adivinando al azar sino mediante un proceso ordenado.
- Eso es P.
- Problemas que son prácticos. Problemas que, usando una especie de atajo, se pueden resolver.

- Existe, sin embargo, otro tipo de problema. Uno para el que no hay atajos.
- Estos problemas tienen solución. De hecho, si tienes una solución y le preguntas al ordenador si es correcta, el ordenador te dirá si lo es o no.
- Sin embargo, si pides al ordenador que resuelva el problema por ti… el ordenador, sin su atajo, simplemente comprobará un número prácticamente infinito de posibilidades hasta que tropiece con la correcta.
- Encontrar la respuesta llevará miles de millones de años a miles de millones de ordenadores.
- Esto es NP.
- Problemas que, a efectos prácticos, simplemente no se pueden resolver

- La gran pregunta sobre P y NP es si son de hecho una sola cosa
- ¿En realidad hay atajos para todos los problemas resolubles? ¿Es que simplemente no hemos descubierto todavía estos métodos esquivos, estos algoritmos perdidos?
- Y si eso es cierto, si todos los problemas NP son simplemente problemas P que esperan nuestra solución… entonces un ordenador podría resolver, a falta de un término mejor, TODO.
- Todos los grandes secretos, desde las colisiones de átomos hasta las colisiones de galaxias, quedarían desvelados. Los veríamos. Serían nuestros.
- Por el contrario, si NP no es igual a P, entonces sencillamente hay problemas –problemas con soluciones– que los ordenadores no pueden resolver.
- Y como tales, dadas nuestras limitaciones, las grandes cuestiones de esta vida quedarían para siempre sin respuesta.
¿Qué hace esta descripción de P vs NP en este tebeo (por cierto, titulado eso, “P vs NP”)? Muy sencillo, la Visión quiere ser normal, quiere ser feliz, quiere que su esposa e hijos (no preguntéis) sean felices. Si la felicidad es un problema P, entonces debe de haber un algoritmo sencillo, un “atajo”, como lo llaman en el texto, que nos permita encontrarla. Pero no lo encuentra, y como predice Agatha Harkness en las últimas viñetas del tebeo, la Visión va a recurrir al enfoque indeterminista: va a probar y probar y probar lo que sea para intentar encontrar la felicidad para su familia. Y el desastre está asegurado. Hasta aquí os quiero contar.

Y como aún llego a tiempo, esta entrada también participa en la Edición 8.5 del Carnaval de Matemáticas cuyo anfitrión es Raíz de 2.

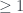 sea la n-ésima es
sea la n-ésima es 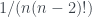 y de que, entonces, la esperanza de esta distribución de probabilidades, es decir, el número promedio de números que tendremos que tomar para superar el 1, es e. Multiplicando por 1000, y quitando partes decimales, obtenéis la aproximación citada por Paulos.
y de que, entonces, la esperanza de esta distribución de probabilidades, es decir, el número promedio de números que tendremos que tomar para superar el 1, es e. Multiplicando por 1000, y quitando partes decimales, obtenéis la aproximación citada por Paulos.
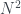 posibles tiradas dobles, en
posibles tiradas dobles, en 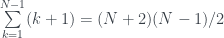 pasaremos de N sin que en la primera tirada lleguemos a N, y este número es mayor que
pasaremos de N sin que en la primera tirada lleguemos a N, y este número es mayor que  si
si 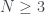 . En concreto, la probabilidad de superar N en dos tiradas de un dado de N caras es de aproximadamente 0.56 si N=4 o N=6; 0.53 si N=12; y 0.52 si N=20.
. En concreto, la probabilidad de superar N en dos tiradas de un dado de N caras es de aproximadamente 0.56 si N=4 o N=6; 0.53 si N=12; y 0.52 si N=20. es un árbol de un solo nodo,
es un árbol de un solo nodo, 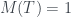 . Si
. Si 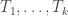 son los subárboles que cuelgan de los hijos de su raíz y
son los subárboles que cuelgan de los hijos de su raíz y 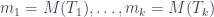 son los números de Matula de estos subárboles y
son los números de Matula de estos subárboles y 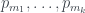 son los primos
son los primos 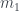 -ésimo,
-ésimo, 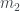 -ésimo, …,
-ésimo, …, 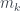 -ésimo, entonces
-ésimo, entonces  .
.
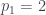 , tenemos que
, tenemos que  . Por otro lado, la raíz de T4 tiene 2 hijos, los dos hojas, por lo que cada uno define un subárbol de un solo nodo, de número de Matula 1. Obtenemos entonces que
. Por otro lado, la raíz de T4 tiene 2 hijos, los dos hojas, por lo que cada uno define un subárbol de un solo nodo, de número de Matula 1. Obtenemos entonces que 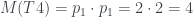 .
.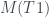 será el producto del octavo primo,
será el producto del octavo primo, 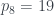 , y del cuarto primo,
, y del cuarto primo,  :
:  . Y como
. Y como 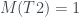 , tenemos finalmente que
, tenemos finalmente que 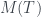 será el producto del primo en la posición 133,
será el producto del primo en la posición 133, 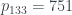 y del primer primo,
y del primer primo,  .
.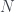 , lo descomponemos en producto de números primos
, lo descomponemos en producto de números primos 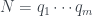 y buscamos cuál es el número de orden de cada
y buscamos cuál es el número de orden de cada  en la lista de todos los primos: digamos que cada
en la lista de todos los primos: digamos que cada 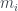 -ésimo. Entonces, la raíz de el árbol T
-ésimo. Entonces, la raíz de el árbol T 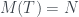 tendrá m hijos, y de ellos colgarán los árboles
tendrá m hijos, y de ellos colgarán los árboles 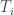 número
número 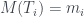 . Naturalmente, si
. Naturalmente, si 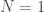 entonces T es el árbol de un solo nodo, por definición.
entonces T es el árbol de un solo nodo, por definición.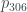 . Por lo tanto el árbol 2017 estará formado por una raíz de la que cuelga un solo hijo, que es la raíz del árbol número 306. Ahora
. Por lo tanto el árbol 2017 estará formado por una raíz de la que cuelga un solo hijo, que es la raíz del árbol número 306. Ahora 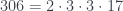 . Como
. Como 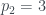 y
y 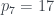 , el árbol 306 está formado por una raíz de la que cuelgan 4 hijos, que son raíces de un árbol número 1 (un solo nodo), dos árboles número 2, y un árbol número 7. Os dejo terminar: el árbol número 2 está formado por una raíz con un único hijo que además es una hoja, y el árbol número 7 (
, el árbol 306 está formado por una raíz de la que cuelgan 4 hijos, que son raíces de un árbol número 1 (un solo nodo), dos árboles número 2, y un árbol número 7. Os dejo terminar: el árbol número 2 está formado por una raíz con un único hijo que además es una hoja, y el árbol número 7 (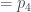 ) está formado por una raíz con un único hijo del que cuelgan dos hijos que son hojas. El resultado es el de la figura que sigue.
) está formado por una raíz con un único hijo del que cuelgan dos hijos que son hojas. El resultado es el de la figura que sigue.
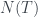 al número de hojas de T e indicamos por
al número de hojas de T e indicamos por 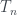 el árbol número
el árbol número  , entonces
, entonces ,
,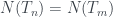 si
si 
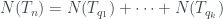 si
si 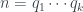 y
y 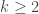
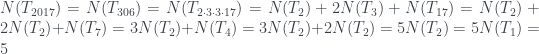
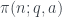 el número de primos
el número de primos 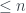 que son congruentes con
que son congruentes con  módulo
módulo  ; supondremos siempre que
; supondremos siempre que 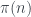 indica el número de todos los primos
indica el número de todos los primos  y
y 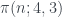 son los números de primos menores o iguales a
son los números de primos menores o iguales a  , la fracción
, la fracción 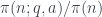 tiende a
tiende a 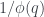 (donde
(donde  es la función de Euler que nos da el número de restos módulo
es la función de Euler que nos da el número de restos módulo 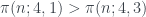 es en
es en  y luego no vuelve a pasar hasta
y luego no vuelve a pasar hasta  . No obstante, un teorema de Littlewood garantiza que el signo de
. No obstante, un teorema de Littlewood garantiza que el signo de  cambia infinitas veces, así que hay infinitas ocasiones en que en las que el 1 gana al 3.
cambia infinitas veces, así que hay infinitas ocasiones en que en las que el 1 gana al 3.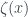 son verdaderas, Rubinstein y Sarnak demostraron en 1994 que, en un cierto sentido específico, la “probabilidad” de que
son verdaderas, Rubinstein y Sarnak demostraron en 1994 que, en un cierto sentido específico, la “probabilidad” de que 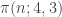 sea mayor que
sea mayor que 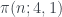 es del 99.6%. Más en general, el teorema de Rubinstein y Sarnak dice que
es del 99.6%. Más en general, el teorema de Rubinstein y Sarnak dice que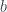 son ambos cuadrados o ambos no cuadrados módulo
son ambos cuadrados o ambos no cuadrados módulo 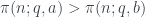 es 0.5
es 0.5 )
)






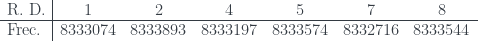
 primos es una miseria.
primos es una miseria.



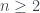 ) de sus dos divisores más pequeños (incluyendo 1 como divisor)? Pensadlo un rato. Ah, ¿que estáis aquí para leer, no para pensar? Vaaaaale, veamos. Si N es impar, sus dos divisores menores serán 1 y un primo impar p, pero entonces N (impar) no puede ser igual a
) de sus dos divisores más pequeños (incluyendo 1 como divisor)? Pensadlo un rato. Ah, ¿que estáis aquí para leer, no para pensar? Vaaaaale, veamos. Si N es impar, sus dos divisores menores serán 1 y un primo impar p, pero entonces N (impar) no puede ser igual a  (par); y si N es par, sus dos divisores menores serán 1 y 2, pero entonces N (par) no puede ser igual a
(par); y si N es par, sus dos divisores menores serán 1 y 2, pero entonces N (par) no puede ser igual a 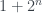 (impar).
(impar).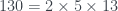 y
y 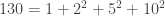 . También encuentra un número Le Monde-959-5 (que es suma de las potencias quintas de sus cuatro primeros divisores): 17864 (podéis comprobarlo, pero en un rato lo volveremos a encontrar). Y en la solución que publicó ayer Le Monde (y que acaba de añadir Xian a su entrada) Le Monde afirma que no hay ningún número Le Monde-959-3, y dan un número Le Monde-959-4, 1419874, y otro número Le Monde-959-5, 1015690. Como el programa de Xian es solo una prueba de concepto, solo busca hasta
. También encuentra un número Le Monde-959-5 (que es suma de las potencias quintas de sus cuatro primeros divisores): 17864 (podéis comprobarlo, pero en un rato lo volveremos a encontrar). Y en la solución que publicó ayer Le Monde (y que acaba de añadir Xian a su entrada) Le Monde afirma que no hay ningún número Le Monde-959-3, y dan un número Le Monde-959-4, 1419874, y otro número Le Monde-959-5, 1015690. Como el programa de Xian es solo una prueba de concepto, solo busca hasta 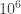 , por lo que no encuentra el primero. Por lo que refiere al segundo… no es suma de las potencias quintas de sus cuatro primeros divisores:
, por lo que no encuentra el primero. Por lo que refiere al segundo… no es suma de las potencias quintas de sus cuatro primeros divisores: 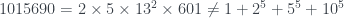 .
.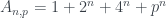 o
o 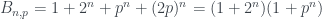
 , ha de pasar:
, ha de pasar: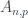 , p ha de dividir a
, p ha de dividir a 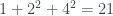 , por lo que
, por lo que  o
o  , y 4 ha de dividir a
, y 4 ha de dividir a 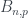 , p ha de dividir a
, p ha de dividir a 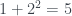 , es decir,
, es decir,  y obtenemos el 130.
y obtenemos el 130.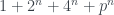 .
. ? Repetimos razonamiento:
? Repetimos razonamiento: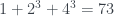 , por lo que
, por lo que  , pero entonces
, pero entonces 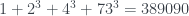 no es es divisible por 4
no es es divisible por 4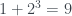 , es decir,
, es decir, 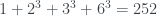 es divisible por 4, por lo que 6 no es uno de sus cuatro divisores más pequeños.
es divisible por 4, por lo que 6 no es uno de sus cuatro divisores más pequeños.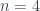 ? Ya sabemos que no hay soluciones de la forma
? Ya sabemos que no hay soluciones de la forma 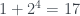 , es decir,
, es decir, 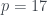 , y resulta que
, y resulta que  , por lo que 1419874 es el único número Le Monde-959-4.
, por lo que 1419874 es el único número Le Monde-959-4.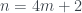 , entonces los números
, entonces los números 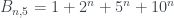 son siempre Le Monde-959-n. Cuando m=0,
son siempre Le Monde-959-n. Cuando m=0, 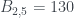 , cuando m=1,
, cuando m=1, 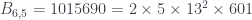 . La demostración general (que 3, 4 y 7 no dividen a
. La demostración general (que 3, 4 y 7 no dividen a 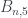 y 5 sí) es sencilla.
y 5 sí) es sencilla.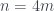 con m impar (es decir,
con m impar (es decir, 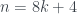 ), entonces los números
), entonces los números 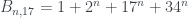 son siempre Le Monde-959-n. Cuando m=1,
son siempre Le Monde-959-n. Cuando m=1, 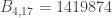 , dado por Le Monde; cuando m=3,
, dado por Le Monde; cuando m=3, 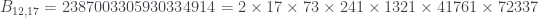 . De nuevo, la demostración general (que 3, 4, 5, 7, 11, 13, 19, 23, 29, 31 no dividen a
. De nuevo, la demostración general (que 3, 4, 5, 7, 11, 13, 19, 23, 29, 31 no dividen a 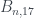 y 17 sí) es sencilla, pero algo larga a mano.
y 17 sí) es sencilla, pero algo larga a mano.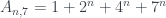 son siempre Le Monde-959-n. Cuando n=5,
son siempre Le Monde-959-n. Cuando n=5, 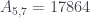 , el que encontró Xian; cuando n=7,
, el que encontró Xian; cuando n=7, 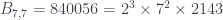 . La demostración general (que 3 y 5 no dividen a
. La demostración general (que 3 y 5 no dividen a 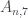 y 4 y 7 sí) también es sencilla y esta vez corta.
y 4 y 7 sí) también es sencilla y esta vez corta.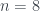 no existe ninguno:
no existe ninguno: 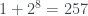 es primo y
es primo y 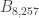 no funciona; para
no funciona; para 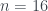 sí que existe uno:
sí que existe uno: 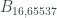 , que no copio aquí porque es un monstruo; para
, que no copio aquí porque es un monstruo; para 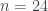 no existe ninguno; para
no existe ninguno; para 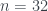 , existe uno:
, existe uno: 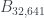 ; para
; para 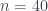 no existe ninguno; para
no existe ninguno; para 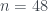 , existe uno:
, existe uno: 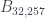 . La pauta es clara, pero tampoco lo he sabido demostrar.
. La pauta es clara, pero tampoco lo he sabido demostrar.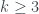 y
y 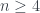 existen números naturales N que son iguales a la suma de las potencias n-ésimas de sus primeros k divisores?
existen números naturales N que son iguales a la suma de las potencias n-ésimas de sus primeros k divisores?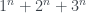 siempre; ejercicio). El resto, lo dejo para algún fan del
siempre; ejercicio). El resto, lo dejo para algún fan del