¿Conocéis el chiste aquel de los dos presos que hace mucho tiempo que comparten celda, y va uno y le pide al otro “Va, cuéntame un chiste”, el otro contesta “El 56” y el primero se parte de risa? Pues últimamente yo estoy en la tesitura de “Va, dame un árbol”, y ya me va bien que me den el 56, pero claro, luego he de saber cuál es. En última instancia, numerar objetos es una manera de ponerles nombre y por lo tanto de poseerlos. Pero entonces es necesario un diccionario que nos permita recuperar los objetos a partir de los números, y si ese diccionario se puede reducir a un algoritmo sencillo, mejor.
En el caso de los árboles (en lo que sigue, por un “árbol” entiendo un árbol en el sentido de la teoría de grafos y con raíz, que en los dibujos corresponde al nodo superior), hay una numeración muy útil: los números de Matula, que se definen recursivamente de la manera siguiente. Si 
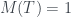
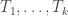
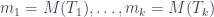
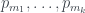
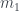
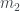
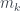

Veamos un ejemplo. Considerad el árbol de la figura, lo llamaremos T (y como hoy es el día del orgullo friki, uso Comic Sans).

Para calcular su número de Matula, hemos de calcular los de sus subárboles T1 y T2. El de T2 és fácil: 1, porque es un solo nodo (una hoja). El número de Matula de T1 será el producto de los primos correspondientes a los de T3 y T4, así que necesitamos calcular primero los números de Matula de T3 y T4. Veamos: la raíz de T3 tiene 3 hijos y los tres son hojas, por lo que cada uno define un subárbol de un solo nodo; por lo tanto, cada uno de estos subárboles tiene número de Matula 1, y como el primer primo es 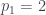

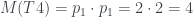
Como T3 y T4 son los árboles número 8 y 4, respectivamente, por la recurrencia, 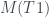
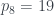


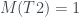
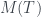
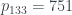

Este proceso se puede invertir. Dado un número 
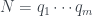

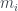
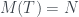
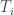
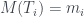
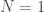
Por ejemplo, ¿cuál el es árbol 2017? 2017 es primo, en concreto 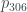
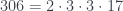
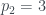
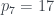
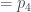

Por lo tanto, cada árbol tiene su número y cada número (natural y a partir de 1) representa un único árbol. Ya los tenemos numerado. Pero además, muchas propiedades de un árbol se pueden obtener a partir de su número, sin tener que reconstruir el árbol. Por ejemplo, su número de hojas. Es fácil comprobar, siguiendo la reconstrucción de un árbol a partir de su número, que si llamamos 
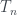

,
si
si
y

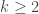
Por ejemplo, el número de hojas de nuestro árbol T número 2017 es
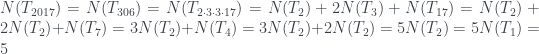
¡Bien!
Otros muchos índices de un árbol se pueden calcular de manera recursiva a partir de su número de Matula. De hecho, ya os podéis imaginar que todo lo que se pueda calcular recurrentemente de hijos a padres se podrá determinar a partir del número de Matula. Si os interesa, este artículo de E. Deutsch explica la manera de calcular una trentena de índices.
Esta entrada participa en la edición 8.4 del Carnaval de Matemáticas, cuyo blog anfitrión es matematicascercanas.

 de
de  para la hojas del árbol o bien su media
para la hojas del árbol o bien su media 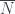 , donde
, donde 
